Before diving into how exactly Nate Silver’s Elo algorithm works I want to tell you a little about Nate Silver. Nate Silver first became famous from his MLB player projection tool PECOTA and managing Baseball Prospectus, a website devoted to baseball “sabermetrics”. Nate became publicly famous for predicting 49/50 states in the 2008 presidential election and was named to Times top 100 most influential people list. In 2012, he went on to predict all 50 states. Since then he created the blog fivethirtyeight.com and publishes data journalism articles.
Silver’s Elo Algorithm: Why care?
Quick answer.. it can make you money. Nate Silver took the Elo algorithm for chess and applied it to sports. On fivethirtyeight he keeps a page dedicated to data driven power rankings. This guy is already famous for predictions so I wanted to share the actual implementation of the algorithm and analyze it’s performance against the spread.[1]The one thing I hate about Nate Silver is that he never goes the extra mile in publishing his methods. He keeps the actual spread performance to a one line comment that it’s not good enough to … Continue reading By using a combination of strength of schedule, team types, and average stats it should be possible to beat Vegas lines and make some money — or at least beat some Stanford undergrads.
From my tests the past few seasons, I’ve found a simple Strength of Schedule (SOS) rating using only scores and home/away information predicts game winners 65-75% of the time (which is in line with published results on the NBA). Against the spread performance is not statistically good enough to beat Vegas spread lines but when combined with other factors it is.
Silver’s Elo Algorithm: Implementation
I’ve compiled the algorithm by reading about his description on fivethirtyeight.com. He doesn’t quite give the implementation details in a convenient way so I’ve listed them here — for the techie people in the audience, the Jupyter notebook I used for this post is available here.
$$R_{0}=1300$$
$$R_{i+1}=K(S_{team}-E_{team})+R_i$$ where R is elo rating, S=1 if the team wins and S=0 for a loss. E represents the expected win probability in Nate’s formula and is defined as $$E_{\text{team}}=\frac{1}{1+10^{\frac{\text{opp_elo}-\text{team_elo}}{400}}}.$$ In chess K is a fixed constant but Nate changes K to handle margin of victory. Nate Silver’s K is $$\text{K}=20\frac{(\text{MOV}_{winner}+3)^{0.8}}{7.5+0.006(\text{elo_difference}_{winner})}.$$ where $$\text{elo_difference}_{winner}=\text{winning_elo}-\text{losing_elo}.$$ Nate also takes into account home advantage by increasing the rating of the home team by 100.
The only other consideration is how to handle seasons. Nate handles this by reverting each team towards a mean of 1505 as in the following formula $$R_{s=i+1}=(0.75)R_{s=i}+(0.25)1505.$$
Proof this is it
Charts don’t lie. [2]They just commonly mislead — not here though 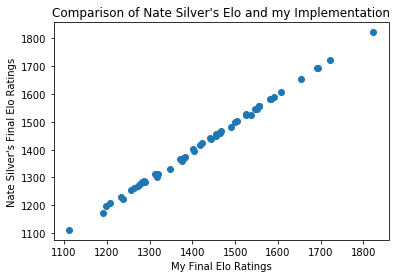
I computed the R-Squared score of a linear fit and found 0.999. The small blips are due to floating point arithmetic and rounding errors.
Accuracy of Elo Predictions
| Predict Away | Predict Home | |
|---|---|---|
| Away Wins | 9772 | 14061 |
| Home Wins | 6083 | 33222 |
The Elo prediction was right 68% of the time. This is pretty remarkable considering how simple it is. Already this beats published models by Stanford students in CS 229 that use over 200 features! God I hope nobody picks on my thesis…
Conclusion
There you have it. Some data behind Nate Silver’s Elo algorithm, code, and a complete description of the model. Be sure to read the bonus topics and leave a comment.
Bonus Topic: Alternate Betting Methods Exploiting Error Profile
Just because Nate Silver’s Elo algorithm has a similar success rate as a coin flip that doesn’t mean you can’t successfully bet with it. Here is the error profile of using his algorithm against the spread for 2012-2014 regular season games. [3]Data from covers.com
| Bet on Away | Bet on Home | |
|---|---|---|
| Away Covers | 757 | 938 |
| Home Covers | 669 | 852 |
Although the success rate at picking teams against the spread is 50.03%, a strategy to only use Nate’s model to bet on away favored teams would have given you a success rate of 53% over 3 years. So maybe there’s something useful with this algorithm that the good people at fivethirtyeight are hiding from their published articles… Hmmm.
Now that we know that just because an algorithm doesn’t perform well for all games that doesn’t mean we can’t use it special cases. Since this Elo implementation is all about strength of schedule and home advantage, it is probably more accurate for home court advantage and teams that go on long streaks against good or bad opponents — the media can overreact. One way you could build a model that understands Elo’s is by adding moving average features to go along with the Elo score.
If you’re curious on what percentage you actually need to be a profitable bettor, I’ve computed the percentage return you receive by betting a fixed amount of money each time. [4]This assumes your payout is -110 on each game.
| Success Rate | Percentage Return |
|---|---|
| 0.50 | -50% |
| 0.51 | -29% |
| 0.52 | -8% |
| 0.53 | 13% |
| 0.54 | 34% |
| 0.55 | 55% |
| 0.56 | 76% |
| 0.57 | 97% |
| 0.58 | 118% |
| 0.59 | 139% |
| 0.60 | 160% |
| 0.61 | 181% |
| 0.62 | 202% |
| 0.63 | 223% |
| 0.64 | 244% |
| 0.65 | 265% |
So at 53% success rate you can “expect” 13% return. If you want to bet with this be my guest. It’s still not good enough for me because a 99% confidence interval shows that your true rate could be 53% and you are only right 48% of the time in a season — too noisy for me — the S&P 500 seems like a better bet than pure Elo . That being said I’m working on a model that is 55% ATS right now that I’m trying to build to 57% by feeding it additional stats. Not sure I’ll share that one 😛
Bonus Topic: Autocorrelation and Markov Models
Auto-correlation (self-correlation) is the tendency of a time series to correlate with a delayed version of itself. For this Elo problem, our goal is to sum up an entire team’s ability with 1 number — granted this isn’t a good assumption but it is what the Elo rating and Nate Silver are trying to do.
I think it’s easiest to show this mathematically. To minimize delayed or “serial” correlations with itself, an Elo rating system should be a markov process. That means that todays rating should only depend on yesterdays rating and earlier information doesn’t add value as in the following formula
$$R_{i}=R_{i-1}=R_{i-1,i-2,i-3,…,0}.$$
That should make sense because all we’re saying is the rating takes into account all the information we have from the past. Autocorrelation helps our Elo values make sense because a 1550 team is always a 1550 team regardless of what they were a week ago.
Bonus Topic: Limitation of 1 Dimensional Rating System and Elo
Do you remember Pokemon? These guys 
Now imagine you tried to rate them and figure out which one’s the best. I’m sure you did but then you would get owned by Gary because although Charmander is pretty good Squirtle destroys him. Water is super effective against fire. The same can be said about NBA teams.
A team that’s great about scoring fast break points should do exceptionally well against a team with turnover problems. If you want to beat Vegas lines day in and day out, you can’t just use one number, Elo, to do everything for you. You gotta do better than that.
Update: fivethirtyeight has posted how they do NFL Elo predictions after I posted this. Thankfully, our code matches. View their github to learn more
References
| ↑1 | The one thing I hate about Nate Silver is that he never goes the extra mile in publishing his methods. He keeps the actual spread performance to a one line comment that it’s not good enough to beat Vegas. |
|---|---|
| ↑2 | They just commonly mislead — not here though |
| ↑3 | Data from covers.com |
| ↑4 | This assumes your payout is -110 on each game. |
Nice write up! I did something similar myself (although a bit hackier) and came to a similar conclusion: the slight edge over Vegas isn’t consistent enough to overcome the noise. With a fictional bankroll of $1,000, this did make a profit in the long run, but it went through a crazy rollercoaster ride along the way.
Have you tried tracking Vegas returns for Nate Silver’s CARMELO model?
Thanks Cameron! I went live with the ELO algorithm 2 year back and it was definitely a rollercoaster.
I want to try CARMELO, it seems like that model should be much better from what fivethirtyeight writes about it. I’m still working on getting enough historical NBA stats and will see if I can write a similar piece to this.
I’m also going to evaluate the Glicko rating system and found a good writeup from a guy who did it for the nhl http://msinilo.pl/blog2/post/p1396/
Hello. Nice article! I actually had great success using 538 by isolating certain game environments in conjunction with Vegas spreads.
Now that 538 is no more, is there another site that provides Elo predictions for NBA?
Great article. This definitely cleared up a few things for me. Thank you.
One thing stands out to me though. If this model has indeed picked with an accuracy of ~68% over the last three years, what does that say about the effect of key players (i.e. all-star level talent) missing games? One would expect this to be an area for error to be introduced. If I’m correct, Elo models don’t account for game-day rosters…
Thanks Jesse. Appreciate you’re comment. I agree, key players missing games would be a great place to start to improve this Elo strength of schedule model. The performance without taking game day rosters into account is remarkable but could probably be improved with game day rosters.
I’m hoping to get quality injury data and test what your saying. I’d wager that star running backs in football make less of a difference than star WR’s or QB’s. As for basketball, I think it could be really interesting to see if stars like Russell Westbrook and all of his triple doubles means that OKC will miss him when he’s out. Or if players tendency to be ball hogs and dictate the style of play can actually hurt teams, e.g. Carmelo Anthony having 60+ points but losing the game. The points make him look like an all-star but it could be hurting his team.
Adding the feature could be tough too. Would a binary variable (key player missing be enough) or would you have to build a model that understands how the missing all-star player would change the style of play. Less offensive rebounds/physical if a key center is out.
I still can’t comprehend how it’s this accurate! Accuracy of 68% is exactly what Vegas has achieved over the same period. The pessimistic side of me questions just how much more precise one get with Vegas being the gold standard and all. I’m inclined to think that the cost-benefit ratio with that endeavour wouldn’t be worth it…
While the Elo model can generate win probabilities and therefore point spreads, any thoughts on if it can be modified to predict team totals?
I agree. It’s insane. Even for the NFL, Elo is consistently very close to Vegas. https://nbviewer.jupyter.org/github/sportsdatadirect/python_tutorials/blob/master/Power%20Rankings.ipynb — scroll to “Performance each season during test period”.
To your question, yes. Elo can generate team totals. First you’d need to make some assumptions on the distribution of team totals. The naive assumption of Gaussian is fine, but some statisticians think the Skellam distribution is a better fit. https://en.wikipedia.org/wiki/Skellam_distribution
All you’d have to do is take the probability of winning and put it in the team total distribution you choose. Could use a team specific distribution or the whole NBA team population. Whatever you choose, you’d probably want to make sure the Elo spread prediction is balanced home_team_total+home_spread=away_team_total.
Great read.
Is there any derivation for the conversion to the point spread (“divide by 28?”)
Thanks. Just took a stab at this and think this is right. Answer comes from home field advantage and average home margin of victory.
Plot the elo_prediction function in the region of Elo ratings e.g. home_rating without home advantage between 1300-1700 and away_rating at 1500.
E_home = 1./(1 + 10 ** ((away_rating – home_rating) / (400.)))
You’ll see the equation linear in this region. Plug in 1600 and 1500 and you should see 64% – this is the implied home field winning percentage in NBA by Nate’s formula, because home_rating=team_rating+100 so the average home_elo_difference must be 100. Also, the expected home MOV is 3.5 (https://fivethirtyeight.com/features/how-we-calculate-nba-elo-ratings/). Divide 100 by 3.5 and round down since 64% is a bit generous and you get 28 as how many Elo points=1 NBA point.
It all comes down to the E_home function. Note that this couples MOV and Elo rating in a linear and constant way. It may be better to use a more complex distribution here. When things are clean and in the linear region of the E_home function this is OK but as you get elo’s that are farther apart it is less valid.
Hey, thanks for this writeup! Very clear and easy to step through. I had a question about the code you posted.
I can’t link to the line of code directly since it’s in a jupyter notebook cell, but I was wondering about this function:
def elo_lookup(fran_id,gameorder):
return full_df[(full_df[‘fran_id’]==fran_id)&(full_df[‘gameorder’]>=gameorder)][‘elo_i’].iloc[0]
which seems to get called whenever you the row you’re looking at contains a team for which you don’t have a preexisting Elo rating.
I don’t see how this code is correct, but perhaps I’m missing something. Won’t this function return the first Elo rating for a team when that team is listed under the fran_id column (as opposed to listed as the opposition, under opp_fran_id)? Meaning, when we look up the Elo rating for the opponent, we can end up getting the opponent’s Elo rating from several games in the future, rather than the Elo rating before the game is played (my understanding is that we’d want the latter)?
As an example, the very first game in Nate Silver’s data is the Huskies (as fran_id) vs. the Knicks (opp_fran_id). The ratings dict is empty, so we’ll need to look up the Elo rating for both. We look up Huskies and get the right result (1300). But the Knicks don’t appear under the fran_id column until game_id 194611110NYK, when they play the Stags. At that point, they have played 3 games. But the way this function is written, that’s the Elo rating we’ll use.
Am I missing something?
Thanks Jash for the comment and reading. I think you missed that the games df is only showing home games whereas the full_df (used in lookup) includes 2 entries per game, one for home and one away. This ensures the first time the Knicks appear in the fran_id column is in the first game (second row of nbaelo.csv https://github.com/rogerfitz/tutorials/blob/master/Nate%20Silver%20ELO/nbaallelo.csv)
To confirm run the model with the first game
m=HeadToHeadModel(list(games[games['gameorder']>STARTING_LOC][:1].iterrows()), silver_elo_update, elo_prediction)
m.train()
m.power_rankings()
This gives [(1, (‘Knicks’, 1306.7232767433188)), (2, (‘Huskies’, 1293.2767232566812))]
Running the first two Knicks games ([:2] gives you
[(1, (‘Stags’, 1309.6521341903551)),
(2, (‘Knicks’, 1297.0711425529637)),
(3, (‘Huskies’, 1293.2767232566812))]
Since Elo is neither created or destroyed we can see that the Knicks lost the exact amount that the Stags gained (9.652=1306.723-1297.0711). If the Knicks rating were wrong then the Knicks elo should be 1290.348.
Let me know if that makes sense or if I messed up somewhere
Ah, I missed that you were using full_df in that function rather than the games df. That clears it up, thank you for clarifying!
No problem. Thanks for reading
Wow, this was a great read! I am doing a Calculus project on how Elo and CARM-Elo works, and this was extremely helpful! Do you have a similar write-up on CARM-Elo that I could find? Thanks!
Thanks Sean. I don’t have a CARM-Elo writeup but the best starting point would be here https://fivethirtyeight.com/methodology/how-our-nba-predictions-work/. If you want to recreate those ratings, the CARMELO player ratings would be the toughest part but if you’re good with understanding network calls you might be able to string a starting point together quickly. https://projects.fivethirtyeight.com/carmelo/ is the base url and player data is accessible using using links such as “https://projects.fivethirtyeight.com/carmelo/lebron-james.json”. Should be able to get a player index to lookup things using the “How good will” X be autocomplete search field
[…] It Up: Blend quantile insights with other cool stuff like Strength of Schedule or team hypes for a well-rounded game […]