
Algorithmia was recently in the news for receiving Series A funding from Google. The concept is pretty cool. Create a marketplace for machine learning algorithms that allows companies without a large R&D team to use algorithms as a black box.
Algorithmia: How it works
I created an account and was given “credits” to call algorithms.
Algorithmia has a ton of algorithms on their marketplace that make it easy to do machine learning tasks.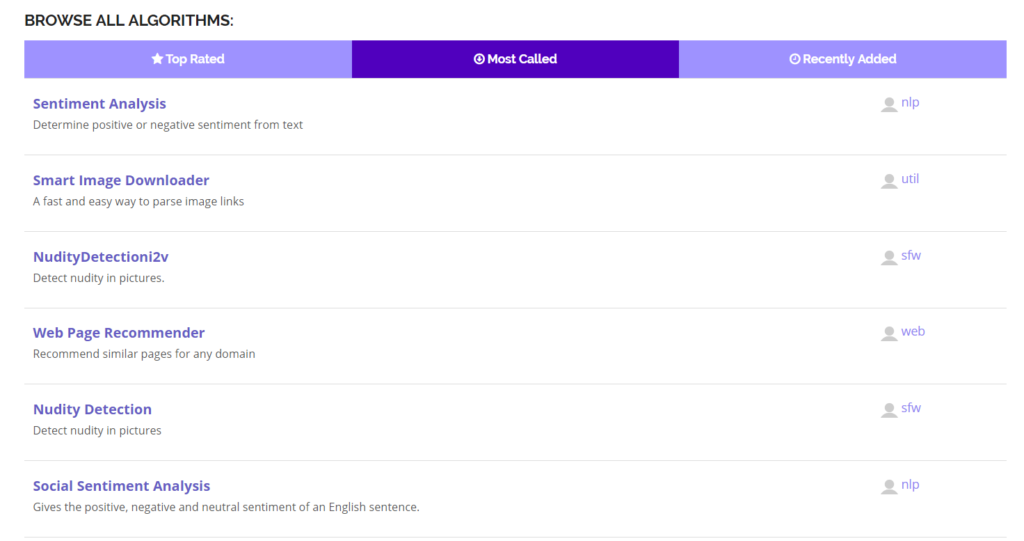
Their “most called” algorithm is sentiment analysis and I’m not surprised. Extracting sentiment from twitter mentions is something that lots of companies and trading algorithms try to do. The standard project is to use the twitter api to extract tweets, use NLP (commonly NLTK in python) to compute sentiment scores, and generate an aggregate opinion about the topic of the tweet. By using Algorithmia, all you need is to supply the text and they’ll take care of the machine learning — which can be difficult for some people to setup.
But let’s get back to my actual experience.
My Experience Using Algorithmia for Lolcat Image OCR
The first thing I wanted to try was Object Character Recognition (OCR) for a project I was stuck on, extracting the text from lolcat pictures because I think lolcats are hilarious. Pictures like these two:


I’m pretty new to doing image processing so I got started with tessarect-ocr and used python — view the jupyter notebook for this post. A full fledged model would probably use edge detection and the specific fonts used by lolcat creators but I just used the image_to_string function of tessarect. Not surprisingly it was pretty bad. The best I got was half the words.

After this I was a bit disappointed and shelved the project. Extracting text was harder than I thought. Then I heard about Algorithmia and gave it a shot. I found two algorithms for OCR that I wanted to try:
- https://algorithmia.com/algorithms/tesseractocr/OCR
- https://algorithmia.com/algorithms/ocr/RecognizeCharacters
Modifying my code to use Algorithmia was as easy as possible. They have an impressive amount of language support and even put my API key in the code sample for me.[1]It’s so nice when API’s do that because finding and copying your API key can be such a pain in the ass sometimes.
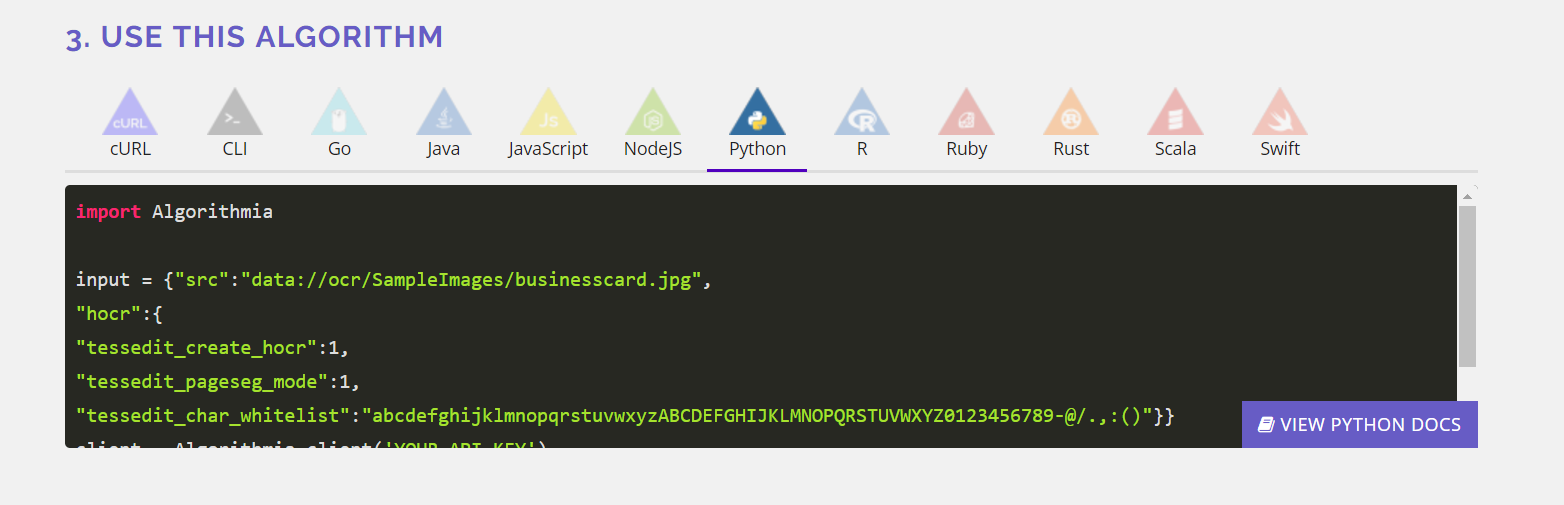
Installing the “Algorithmia” package was simply pip install algorithmia.
Results
Although it was amazingly easy to get started I was disappointed in the performance of the ocr algorithms. My basic OCR — while still bad — performed better. Maybe this is because Lolcats are a very specific application of text extraction but I was hoping the published algorithms would beat out of the box library results.
This doesn’t mean that Algorithmia is a bad site. I think they need their killer algorithm, sentiment analysis may be it. Besides that they have some useful data scraping features. All the time on Upwork I see job proposals looking for freelancing to scrape emails and data from business cards. Marketplaces like Algorithmia are perfect to help scripters that can setup python but don’t know computers well enough to mess with all the C binaries needed for image recognition.
Overall I was very impressed with how well developed the Algorithmia platform is and am excited to watch them grow.
I have no affiliation with any of the companies mentioned and this is my honest, unsolicited review.
Get the code for this post on my github
References
| ↑1 | It’s so nice when API’s do that because finding and copying your API key can be such a pain in the ass sometimes. |
|---|